Landmark-of-medical-agent
🚀 The Landscape of Medical Agents: A Survey
🚀 MedMASLab:A Framework for Multimodal Medical Multi-Agent Systems

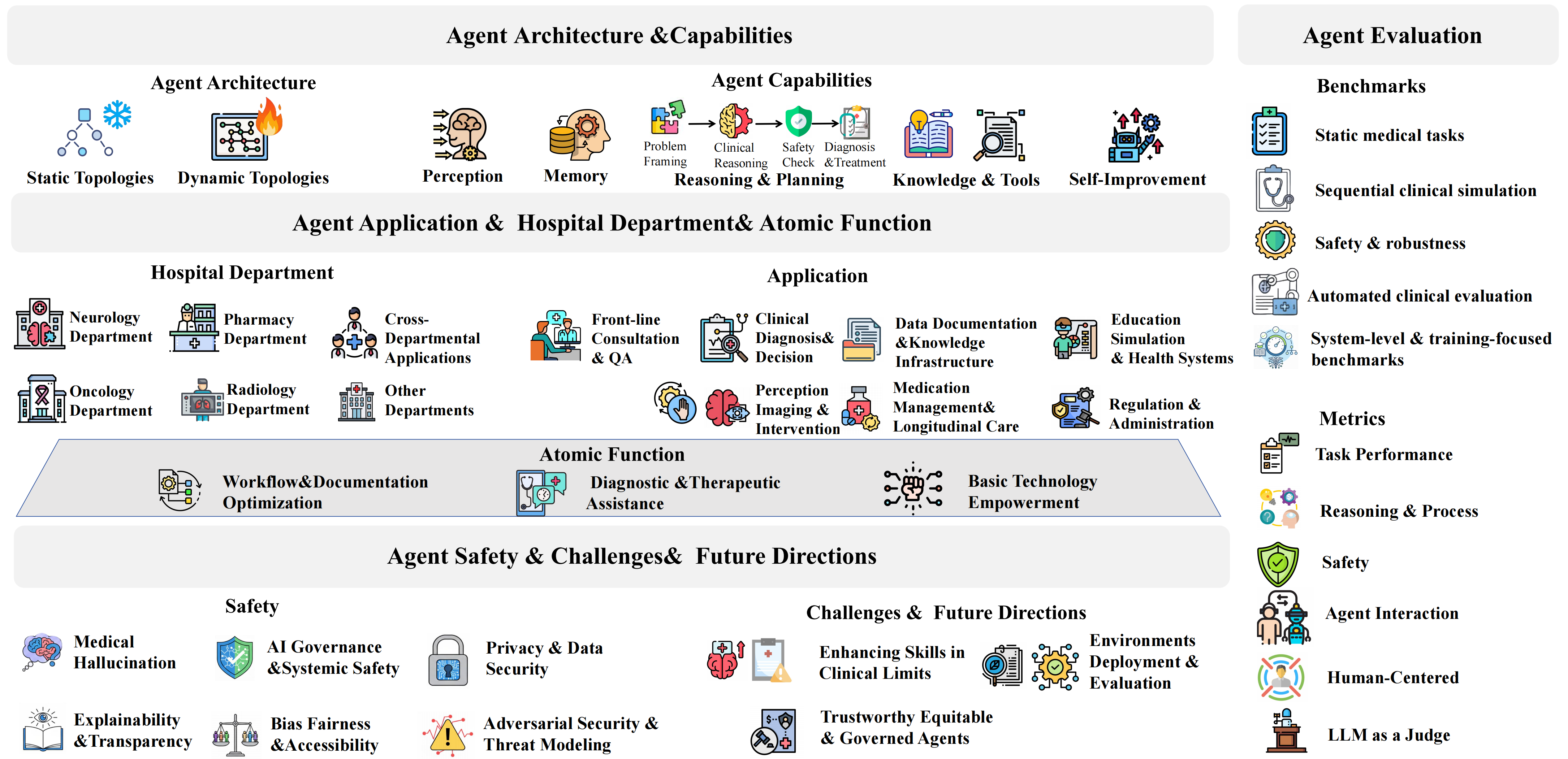
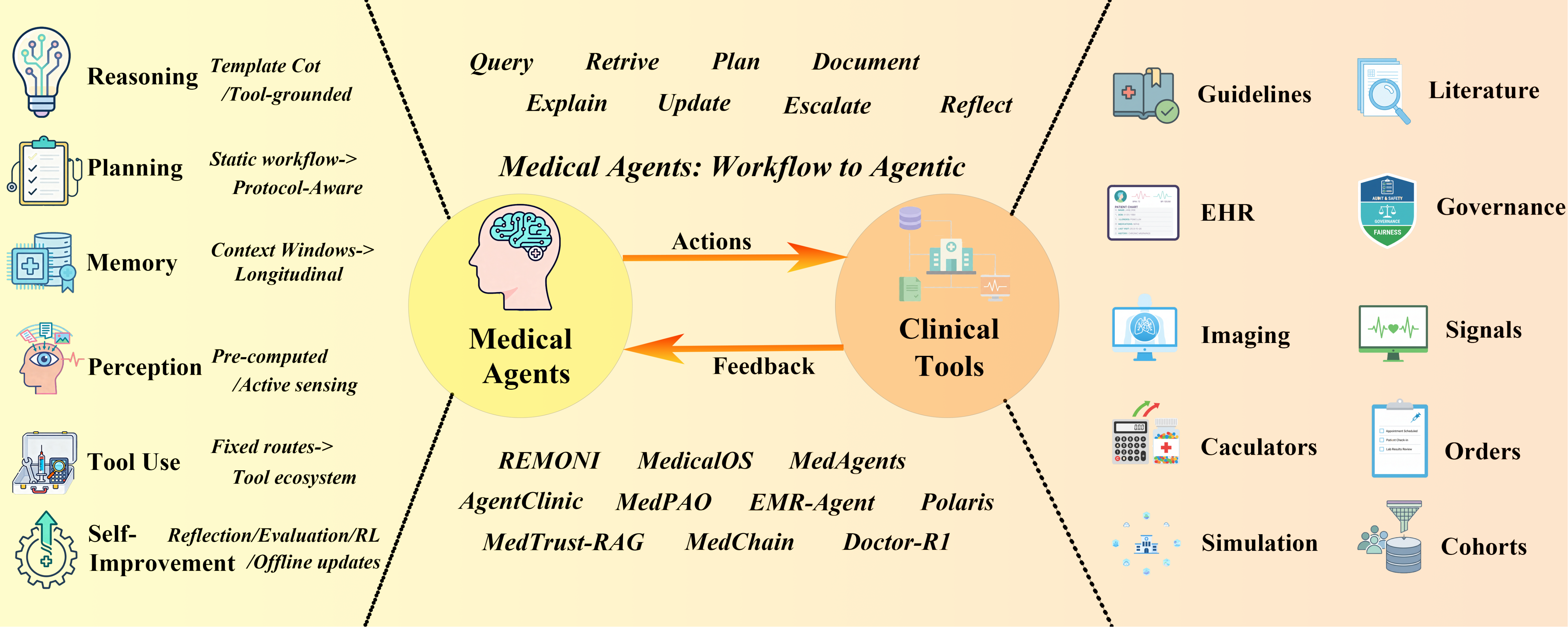
🌟 Overview
This is the official repository for the survey paper: The Landscape of Medical Agents. This repository is a comprehensive and systematic research resource library for medical agents, dedicated to organizing and tracking the latest research progress, application practices, and technological developments of AI intelligent agents in the medical and health field. This investigative project covers the entire ecosystem from basic technical capabilities to clinical actual deployment, providing an authoritative research map for medical AI researchers, clinical practitioners, and system developers.
🔥 News
[2026/3/10] We release :A Unified Orchestration Framework for Benchmarking Multimodal Medical Multi-Agent Systems! Click here to visit: medmaslab
🔥 Add Your Paper in our Repo and Survey!!!!! Join our group and post your agent work!!!!
[-] You are welcome to give us an issue or PR for your medical agent work !!!!!
[-] Note that: Due to the huge paper in Arxiv, we are sorry to cover all in our survey. You can directly present a PR into this repo and we will record it for next version update of our survey.
[-] Our survey will be updated in 2026.3.
🤝 Thanks
If you think this project is useful and inspiring, we would greatly appreciate it if you could give us a Star to show your support! Your support is of great significance to us, as it encourages us to continue improving and developing this project.
📖 Keywords
Medical Agents, Clinical Workflows, Safety, Governance and Evaluation
🌟 Contributing
We will try to keep this list updated. If you find any errors or any missed paper, please don’t hesitate to open issues or pull request.Please follow the instruction in CONTRIBUTING.md if you want to make one. Additionally, if you want to have any other issue, please add this wechat group.

🤝 Main Contacts
- Xiaobin Hu - ben0xiaobin0hu1@nus.edu.sg
Citation
@article{hu2025landscape, title={The Landscape of Medical Agents: A Survey}, author={Hu, Xiaobin and Qian, Yunhang and Yu, Jiaquan and Liu, Jingjing and Tang, Peng and Ji, Xiaozhong and Xu, Chengming and Liu, Jiawei and Yan, Xiaoxiao and Yu, Xinlei and others}, journal={Authorea Preprints}, year={2025}, publisher={Authorea} }@misc{qian2026medmaslabunifiedorchestrationframework, title={MedMASLab: A Unified Orchestration Framework for Benchmarking Multimodal Medical Multi-Agent Systems}, author={Yunhang Qian and Xiaobin Hu and Jiaquan Yu and Siyang Xin and Xiaokun Chen and Jiangning Zhang and Peng-Tao Jiang and Jiawei Liu and Hongwei Bran Li}, year={2026}, eprint={2603.09909}, archivePrefix={arXiv}, primaryClass={cs.AI}, url={https://arxiv.org/abs/2603.09909}, }🌟 Table of Contents
- Latest Papers
- Papers by Category
✨ Latest Papers
🚀 Year-2026
January
| Title | Paper-link | Sections | | — | — | — | | EvoClinician: A Self-Evolving Agent for Multi-Turn Medical Diagnosis via Test-Time Evolutionary Learning | Paper | benchmark | | Structure-constrained Language-informed Diffusion Model for Unpaired Low-dose Computed Tomography Angiography Reconstruction | Paper | application | | Scaling Medical Reasoning Verification via Tool-Integrated Reinforcement Learning | Paper | benchmark | | Strong Reasoning Isn’t Enough: Evaluating Evidence Elicitation in Interactive Diagnosis | Paper | benchmark | | DEEPMED: Building a Medical DeepResearch Agent via Multi-hop Med-Search Data and Turn-Controlled Agentic Training & Inference | Paper | benchmark | | Bayesian Multiple Testing for Suicide Risk in Pharmacoepidemiology: Leveraging Co-Prescription Patterns | Paper | framework | | AgentsEval: Clinically Faithful Evaluation of Medical Imaging Reports via Multi-Agent Reasoning | Paper | benchmark | | Automated Rubrics for Reliable Evaluation of Medical Dialogue Systems | Paper | framework | | Query-Efficient Agentic Graph Extraction Attacks on GraphRAG Systems | Paper | benchmark | | HyperWalker: Dynamic Hypergraph-Based Deep Diagnosis for Multi-Hop Clinical Modeling across EHR and X-Ray in Medical VLMs | Paper | framework | | AgentEHR: Advancing Autonomous Clinical Decision-Making via Retrospective Summarization | Paper | benchmark | | Towards Efficient and Robust Linguistic Emotion Diagnosis for Mental Health via Multi-Agent Instruction Refinement | Paper | benchmark | | Improving the Safety and Trustworthiness of Medical AI via Multi-Agent Evaluation Loops | Paper | framework | | MedConsultBench: A Full-Cycle, Fine-Grained, Process-Aware Benchmark for Medical Consultation Agents | Paper | benchmark | | Knowing When to Abstain: Medical LLMs Under Clinical Uncertainty | Paper | benchmark | | A multitask framework for automated interpretation of multi-frame right upper quadrant ultrasound in clinical decision support | Paper | benchmark | | Medication counseling with large language models: balancing flexibility and rigidity | Paper | benchmark | | MMedExpert-R1: Strengthening Multimodal Medical Reasoning via Domain-Specific Adaptation and Clinical Guideline Reinforcement | Paper | benchmark | | Japanese AI Agent System on Human Papillomavirus Vaccination: System Design | Paper | framework | | ART: Action-based Reasoning Task Benchmarking for Medical AI Agents | Paper | benchmark | | Route, Retrieve, Reflect, Repair: Self-Improving Agentic Framework for Visual Detection and Linguistic Reasoning in Medical Imaging | Paper | framework | | MEDVISTAGYM: A Scalable Training Environment for Thinking with Medical Images via Tool-Integrated Reinforcement Learning | Paper | benchmark | | MedEinst: Benchmarking the Einstellung Effect in Medical LLMs through Counterfactual Differential Diagnosis | Paper | benchmark | | Modeling Descriptive Norms in Multi-Agent Systems: An Auto-Aggregation PDE Framework with Adaptive Perception Kernels | Paper | benchmark | | Value of Information: A Framework for Human-Agent Communication | Paper | framework | | DemMA: Dementia Multi-Turn Dialogue Agent with Expert-Guided Reasoning and Action Simulation | Paper | framework | | Tool-MAD: A Multi-Agent Debate Framework for Fact Verification with Diverse Tool Augmentation and Adaptive Retrieval | Paper | benchmark | | Staged Voxel-Level Deep Reinforcement Learning for 3D Medical Image Segmentation with Noisy Annotations | Paper | benchmark | | RadDiff: Describing Differences in Radiology Image Sets with Natural Language | Paper | benchmark | | IBISAgent: Reinforcing Pixel-Level Visual Reasoning in MLLMs for Universal Biomedical Object Referring and Segmentation | Paper | benchmark | | MedDialogRubrics: A Comprehensive Benchmark and Evaluation Framework for Multi-turn Medical Consultations in Large Language Models | Paper | benchmark | | Causal-Enhanced AI Agents for Medical Research Screening | Paper | medical | | Entropy-Adaptive Fine-Tuning: Resolving Confident Conflicts to Mitigate Forgetting | Paper | medical | | Bayesian Orchestration of Multi-LLM Agents for Cost-Aware Sequential Decision-Making | Paper | framework | | An Explainable Agentic AI Framework for Uncertainty-Aware and Abstention-Enabled Acute Ischemic Stroke Imaging Decisions | Paper | benchmark |
February
| Title | Paper-link | Sections | | — | — | — | | Evaluating Stochasticity in Deep Research Agents | Paper | framework | | Agency and Architectural Limits: Why Optimization-Based Systems Cannot Be Norm-Responsive | Paper | medical | | Can Agents Distinguish Visually Hard-to-Separate Diseases in a Zero-Shot Setting? A Pilot Study | Paper | benchmark | | Which Tool Response Should I Trust? Tool-Expertise-Aware Chest X-ray Agent with Multimodal Agentic Learning | Paper | framework | | ALPACA: A Reinforcement Learning Environment for Medication Repurposing and Treatment Optimization in Alzheimer’s Disease | Paper | medical | | LAMMI-Pathology: A Tool-Centric Bottom-Up LVLM-Agent Framework for Molecularly Informed Medical Intelligence in Pathology | Paper | framework | | NutriOrion: A Hierarchical Multi-Agent Framework for Personalized Nutrition Intervention Grounded in Clinical Guidelines | Paper | framework | | 4D-UNet improves clutter rejection in human transcranial contrast enhanced ultrasound | Paper | benchmark | | INSURE-Dial: A Phase-Aware Conversational Dataset & Benchmark for Compliance Verification and Phase Detection | Paper | benchmark | | 3DMedAgent: Unified Perception-to-Understanding for 3D Medical Analysis | Paper | benchmark | | Agentic Unlearning: When LLM Agent Meets Machine Unlearning | Paper | benchmark | | MedClarify: An information-seeking AI agent for medical diagnosis with case-specific follow-up questions | Paper | medical | | Agentic AI, Medical Morality, and the Transformation of the Patient-Physician Relationship | Paper | framework | | A Multi-Agent Framework for Medical AI: Leveraging Fine-Tuned GPT, LLaMA, and DeepSeek R1 for Evidence-Based and Bias-Aware Clinical Query Processing | Paper | benchmark | | MedScope: Incentivizing “Think with Videos” for Clinical Reasoning via Coarse-to-Fine Tool Calling | Paper | benchmark | | Implicit Bias in LLMs for Transgender Populations | Paper | application | | TRACE: Temporal Reasoning via Agentic Context Evolution for Streaming Electronic Health Records (EHRs) | Paper | framework | | MedXIAOHE: A Comprehensive Recipe for Building Medical MLLMs | Paper | benchmark | | Advancing AI Trustworthiness Through Patient Simulation: Risk Assessment of Conversational Agents for Antidepressant Selection | Paper | framework | | LiveMedBench: A Contamination-Free Medical Benchmark for LLMs with Automated Rubric Evaluation | Paper | benchmark | | Closing Reasoning Gaps in Clinical Agents with Differential Reasoning Learning | Paper | benchmark | | CoMMa: Contribution-Aware Medical Multi-Agents From A Game-Theoretic Perspective | Paper | benchmark | | SynthAgent: A Multi-Agent LLM Framework for Realistic Patient Simulation – A Case Study in Obesity with Mental Health Comorbidities | Paper | framework | | MedCoG: Maximizing LLM Inference Density in Medical Reasoning via Meta-Cognitive Regulation | Paper | benchmark | | JADE: Expert-Grounded Dynamic Evaluation for Open-Ended Professional Tasks | Paper | benchmark | | Do LLMs Act Like Rational Agents? Measuring Belief Coherence in Probabilistic Decision Making | Paper | application | | Pruning Minimal Reasoning Graphs for Efficient Retrieval-Augmented Generation | Paper | benchmark | | Agentic AI in Healthcare & Medicine: A Seven-Dimensional Taxonomy for Empirical Evaluation of LLM-based Agents | Paper | benchmark | | MedSAM-Agent: Empowering Interactive Medical Image Segmentation with Multi-turn Agentic Reinforcement Learning | Paper | benchmark | | Privasis: Synthesizing the Largest “Public” Private Dataset from Scratch | Paper | benchmark | | Perfusion Imaging and Single Material Reconstruction in Polychromatic Photon Counting CT | Paper | medical | | RE-MCDF: Closed-Loop Multi-Expert LLM Reasoning for Knowledge-Grounded Clinical Diagnosis | Paper | benchmark | | MedBeads: An Agent-Native, Immutable Data Substrate for Trustworthy Medical AI | Paper | framework | | ExperienceWeaver: Optimizing Small-sample Experience Learning for LLM-based Clinical Text Improvement | Paper | benchmark | | Enhancing Imaging Depth and Sensitivity in Reflectance Mode Near Infrared Optical Imaging with Scatter Reducing Agents | Paper | application |
March
| Title | Paper-link | Sections | | — | — | — | | Symphony for Medical Coding: A Next-Generation Agentic System for Scalable and Explainable Medical Coding | Paper | benchmark | | Knowledge database development by large language models for countermeasures against viruses and marine toxins | Paper | medical | | Towards a Medical AI Scientist | Paper | framework | | FeDMRA: Federated Incremental Learning with Dynamic Memory Replay Allocation | Paper | benchmark | | Improving Clinical Diagnosis with Counterfactual Multi-Agent Reasoning | Paper | benchmark | | MediHive: A Decentralized Agent Collective for Medical Reasoning | Paper | benchmark | | Autonomous Agent-Orchestrated Digital Twins (AADT): Leveraging the OpenClaw Framework for State Synchronization in Rare Genetic Disorders | Paper | framework | | Doctorina MedBench: End-to-End Evaluation of Agent-Based Medical AI | Paper | benchmark | | Colon-Bench: An Agentic Workflow for Scalable Dense Lesion Annotation in Full-Procedure Colonoscopy Videos | Paper | benchmark | | OMIND: Framework for Knowledge Grounded Finetuning and Multi-Turn Dialogue Benchmark for Mental Health LLMs | Paper | benchmark | | Belief-Driven Multi-Agent Collaboration via Approximate Perfect Bayesian Equilibrium for Social Simulation | Paper | benchmark | | MedOpenClaw: Auditable Medical Imaging Agents Reasoning over Uncurated Full Studies | Paper | benchmark | | Multi-Agent Reasoning with Consistency Verification Improves Uncertainty Calibration in Medical MCQA | Paper | benchmark | | RVLM: Recursive Vision-Language Models with Adaptive Depth | Paper | framework | | CarePilot: A Multi-Agent Framework for Long-Horizon Computer Task Automation in Healthcare | Paper | benchmark | | Dialogue to Question Generation for Evidence-based Medical Guideline Agent Development | Paper | benchmark | | 3D-LLDM: Label-Guided 3D Latent Diffusion Model for Improving High-Resolution Synthetic MR Imaging in Hepatic Structure Segmentation | Paper | benchmark | | From Physician Expertise to Clinical Agents: Preserving, Standardizing, and Scaling Physicians’ Medical Expertise with Lightweight LLM | Paper | framework | | Training a Large Language Model for Medical Coding Using Privacy-Preserving Synthetic Clinical Data | Paper | medical | | Privacy-Preserving EHR Data Transformation via Geometric Operators: A Human-AI Co-Design Technical Report | Paper | framework | | Can LLM Agents Generate Real-World Evidence? Evaluating Observational Studies in Medical Databases | Paper | benchmark | | Cerebra: A Multidisciplinary AI Board for Multimodal Dementia Characterization and Risk Assessment | Paper | benchmark | | Agentic Automation of BT-RADS Scoring: End-to-End Multi-Agent System for Standardized Brain Tumor Follow-up Assessment | Paper | medical | | ARYA: A Physics-Constrained Composable & Deterministic World Model Architecture | Paper | benchmark | | Anatomical Prior-Driven Framework for Autonomous Robotic Cardiac Ultrasound Standard View Acquisition | Paper | benchmark | | TuLaBM: Tumor-Biased Latent Bridge Matching for Contrast-Enhanced MRI Synthesis | Paper | benchmark | | OpenHospital: A Thing-in-itself Arena for Evolving and Benchmarking LLM-based Collective Intelligence | Paper | benchmark | | MedPriv-Bench: Benchmarking the Privacy-Utility Trade-off of Large Language Models in Medical Open-End Question Answering | Paper | benchmark | | Towards Equitable Robotic Furnishing Agents for Aging-in-Place: ADL-Grounded Design Exploration | Paper | other | | EviAgent: Evidence-Driven Agent for Radiology Report Generation | Paper | benchmark | | OmniCompliance-100K: A Multi-Domain, Rule-Grounded, Real-World Safety Compliance Dataset | Paper | benchmark | | Beyond Medical Diagnostics: How Medical Multimodal Large Language Models Think in Space | Paper | benchmark | | Six Interventions for the Responsible and Ethical Implementation of Medical AI Agents | Paper | benchmark | | TheraAgent: Multi-Agent Framework with Self-Evolving Memory and Evidence-Calibrated Reasoning for PET Theranostics | Paper | framework | | Increasing intelligence in AI agents can worsen collective outcomes | Paper | medical | | A Semi-Decentralized Approach to Multiagent Control | Paper | benchmark | | When OpenClaw Meets Hospital: Toward an Agentic Operating System for Dynamic Clinical Workflows | Paper | benchmark | | UAV-MARL: Multi-Agent Reinforcement Learning for Time-Critical and Dynamic Medical Supply Delivery | Paper | benchmark | | Human-AI Co-reasoning for Clinical Diagnosis with Evidence-Integrated Language Agent | Paper | benchmark | | MedMASLab: A Unified Orchestration Framework for Benchmarking Multimodal Medical Multi-Agent Systems | Paper | benchmark | | Meissa: Multi-modal Medical Agentic Intelligence | Paper | benchmark | | RexDrug: Reliable Multi-Drug Combination Extraction through Reasoning-Enhanced LLMs | Paper | benchmark | | Empowering Locally Deployable Medical Agent via State Enhanced Logical Skills for FHIR-based Clinical Tasks | Paper | benchmark | | Computational Pathology in the Era of Emerging Foundation and Agentic AI – International Expert Perspectives on Clinical Integration and Translational Readiness | Paper | benchmark | | Shifting Adaptation from Weight Space to Memory Space: A Memory-Augmented Agent for Medical Image Segmentation | Paper | benchmark | | Evolving Medical Imaging Agents via Experience-driven Self-skill Discovery | Paper | benchmark | | MedCoRAG: Interpretable Hepatology Diagnosis via Hybrid Evidence Retrieval and Multispecialty Consensus | Paper | framework | | Model Medicine: A Clinical Framework for Understanding, Diagnosing, and Treating AI Models | Paper | framework | | Do Mixed-Vendor Multi-Agent LLMs Improve Clinical Diagnosis? | Paper | framework | | A Multi-Agent Framework for Interpreting Multivariate Physiological Time Series | Paper | medical | | MIND: Unified Inquiry and Diagnosis RL with Criteria Grounded Clinical Supports for Psychiatric Consultation | Paper | framework | | From Conflict to Consensus: Boosting Medical Reasoning via Multi-Round Agentic RAG | Paper | benchmark | | ATPO: Adaptive Tree Policy Optimization for Multi-Turn Medical Dialogue | Paper | benchmark | | CARE: Towards Clinical Accountability in Multi-Modal Medical Reasoning with an Evidence-Grounded Agentic Framework | Paper | benchmark | | TARSE: Test-Time Adaptation via Retrieval of Skills and Experience for Reasoning Agents | Paper | benchmark | | MedCollab: Causal-Driven Multi-Agent Collaboration for Full-Cycle Clinical Diagnosis via IBIS-Structured Argumentation | Paper | benchmark | | DUCX: Decomposing Unfairness in Tool-Using Chest X-ray Agents | Paper | framework | | OPGAgent: An Agent for Auditable Dental Panoramic X-ray Interpretation | Paper | benchmark |
April
| Title | Paper-link | Sections | | — | — | — | | Beyond the Individual: Virtualizing Multi-Disciplinary Reasoning for Clinical Intake via Collaborative Agents | Paper | application | | XrayClaw: Cooperative-Competitive Multi-Agent Alignment for Trustworthy Chest X-ray Diagnosis | Paper | benchmark | | ECG Foundation Models and Medical LLMs for Agentic Cardiovascular Intelligence at the Edge: A Review and Outlook | Paper | framework | | Safety, Security, and Cognitive Risks in World Models | Paper | medical | | CARE: Privacy-Compliant Agentic Reasoning with Evidence Discordance | Paper | benchmark | | Collaborative AI Agents and Critics for Fault Detection and Cause Analysis in Network Telemetry | Paper | medical |
🚀 Year-2025
🚀 Year-2024
🚀 Year-2023
🚀 Earlier
✨ Papers by Category
🚀 1. Capability
1.1 Planning
1.2 Tool Use
1.3 Memory
1.4 Self-Improvement
1.5 Reasoning
1.6 Perception
| Title | GitHub | Year |
|---|---|---|
| Navigation Through Endoluminal Channels Using Q-Learning | Not Available | 2023 |
| Agent-Based Uncertainty Awareness Improves Automated Radiology Report Labeling with an Open-Source Large Language Model | Not Available | 2025 |
| ChatMyopia: An AI Agent for Pre-consultation Education in Primary Eye Care Settings | Not Available | 2025 |
| Vision-language model for report generation and outcome prediction in CT pulmonary angiogram | GitHub | 2025 |
| MedCoAct: Confidence-Aware Multi-Agent Collaboration for Complete Clinical Decision | Not Available | 2025 |
| MedRepBench: A Comprehensive Benchmark for Medical Report Interpretation | Not Available | 2025 |
| T-agent: A term-aware agent for medical dialogue generation | Not Available | 2024 |
1.7 Others (continual learning, uncertainty)
🚀 2. Atomic Function
2.1 Basic Technology Empowerment
2.2 Core Diagnostic & Therapeutic Assistance
2.3 Workflow & Documentation Optimization
🚀 3. Application
3.1 Intake & Clinical Dialogue
3.2 Virtual MDT Teams & Multimodal Reasoning
3.3 Treatment Procedures
3.4 Chronic Disease Management & Prescription Safety
3.5 Documentation, Coding & Knowledge Infrastructure
| Title | GitHub | Year |
|---|---|---|
| Benchmarking Automatic Speech Recognition coupled LLM Modules for Medical Diagnostics | Not Available | 2025 |
| Exploring llm multi-agents for icd coding | Not Available | 2024 |
| Code Like Humans: A Multi-Agent Solution for Medical Coding | GitHub | 2025 |
3.6 Simulation & Support Systems
| Title | GitHub | Year |
|---|---|---|
| Towards anatomy education with generative AI-based virtual assistants in immersive virtual reality environments | Not Available | 2024 |
| When Avatars Have Personality: Effects on Engagement and Communication in Immersive Medical Training | Not Available | 2025 |
3.7 Regulation, Payer Workflows & Administrative Automation
| Title | GitHub | Year |
|---|---|---|
| Large language models as agents in the clinic | Not Available | 2023 |
| Enhancing diagnostic accuracy through multi-agent conversations: using large language models to mitigate cognitive bias | Not Available | 2024 |
| A hybrid reinforcement learning and knowledge graph framework for financial risk optimization in healthcare systems | Not Available | 2025 |
🚀 4. Safety
4.1 Medical Hallucination
4.2 Privacy & Data-Security
4.3 Explainability & Transparency
4.4 Adversarial Security & Threat Modeling
| Title | GitHub | Year |
|---|---|---|
| Adversarial attacks on large language models in medicine | Not Available | 2024 |
| On the resilience of llm-based multi-agent collaboration with faulty agents | Not Available | 2024 |
| Data Poisoning Vulnerabilities Across Healthcare AI Architectures: A Security Threat Analysis | Not Available | 2025 |
| Emerging cyber attack risks of medical ai agents | Not Available | 2025 |
| Red-teaming llm multi-agent systems via communication attacks | Not Available | 2025 |
| TAMAS: Benchmarking Adversarial Risks in Multi-Agent LLM Systems | Not Available | 2025 |
| Towards safe ai clinicians: A comprehensive study on large language model jailbreaking in healthcare | Not Available | 2025 |
4.5 AI Governance & Systemic Safety
| Title | GitHub | Year |
|---|---|---|
| Levels of autonomy and safety assurance for AI-Based clinical decision systems | Not Available | 2023 |